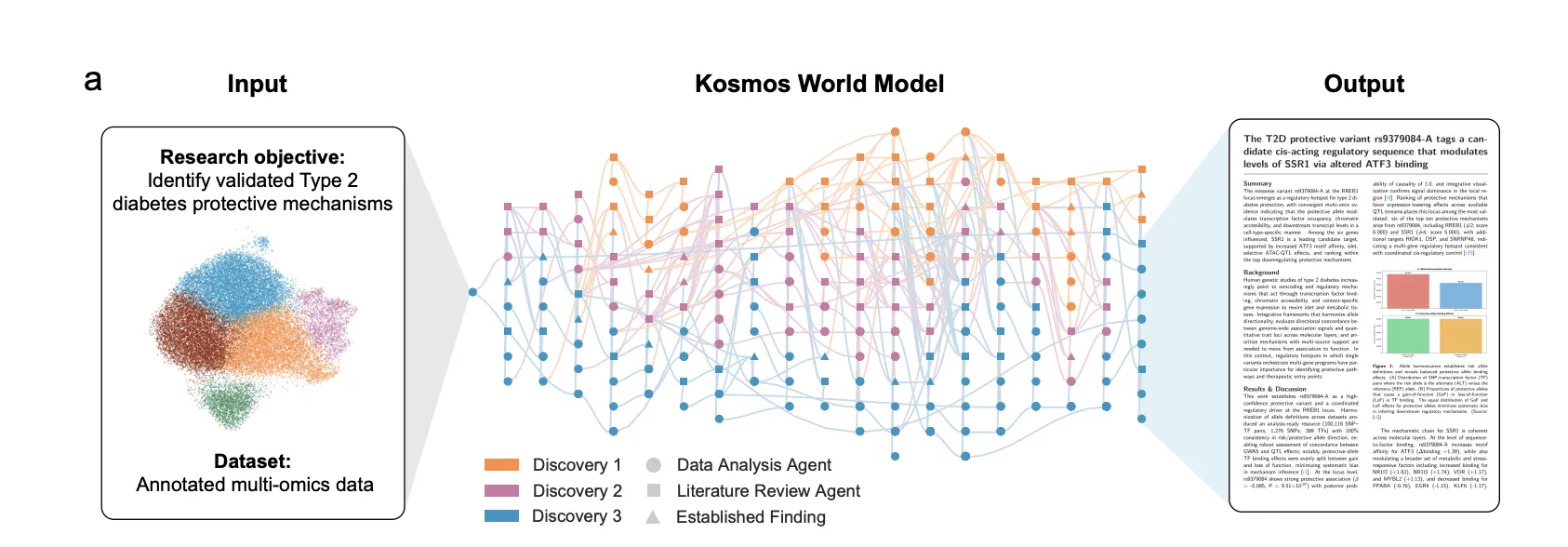
In this tutorial, we explore how to build agentic systems that think beyond a single interaction by utilizing memory as a core capability. We walk through how we design episodic memory to store experiences and semantic memory to capture long-term patterns, allowing the agent to evolve its behaviour over multiple sessions. As we implement planning, acting, revising, and reflecting, we see how the agent gradually adapts to user preferences and becomes more autonomous. By the end, we understand how memory-driven reasoning helps us create agents that feel more contextual, consistent, and intelligent with every interaction. Check out the FULL CODES here.
import numpy as np
from collections import defaultdict
import json
from datetime import datetime
import pickle
class EpisodicMemory:
def __init__(self, capacity=100):
self.capacity = capacity
self.episodes = []
def store(self, state, action, outcome, timestamp=None):
if timestamp is None:
timestamp = datetime.now().isoformat()
episode = {
'state': state,
'action': action,
'outcome': outcome,
'timestamp': timestamp,
'embedding': self._embed(state, action, outcome)
}
self.episodes.append(episode)
if len(self.episodes) > self.capacity:
self.episodes.pop(0)
def _embed(self, state, action, outcome):
text = f"{state} {action} {outcome}".lower()
return hash(text) % 10000
def retrieve_similar(self, query_state, k=3):
if not self.episodes:
return []
query_emb = self._embed(query_state, "", "")
scores = [(abs(ep['embedding'] - query_emb), ep) for ep in self.episodes]
scores.sort(key=lambda x: x[0])
return [ep for _, ep in scores[:k]]
def get_recent(self, n=5):
return self.episodes[-n:]
class SemanticMemory:
def __init__(self):
self.preferences = defaultdict(float)
self.patterns = defaultdict(list)
self.success_rates = defaultdict(lambda: {'success': 0, 'total': 0})
def update_preference(self, key, value, weight=1.0):
self.preferences[key] = 0.9 * self.preferences[key] + 0.1 * weight * value
def record_pattern(self, context, action, success):
pattern_key = f"{context}_{action}"
self.patterns[context].append((action, success))
self.success_rates[pattern_key]['total'] += 1
if success:
self.success_rates[pattern_key]['success'] += 1
def get_best_action(self, context):
if context not in self.patterns:
return None
action_scores = defaultdict(lambda: {'success': 0, 'total': 0})
for action, success in self.patterns[context]:
action_scores[action]['total'] += 1
if success:
action_scores[action]['success'] += 1
best_action = max(action_scores.items(), key=lambda x: x[1]['success'] / max(x[1]['total'], 1))
return best_action[0] if best_action[1]['total'] > 0 else None
def get_preference(self, key):
return self.preferences.get(key, 0.0)We define the core memory structures that our agent relies on. We build episodic memory to capture specific experiences and semantic memory to generalize patterns over time. As we establish these foundations, we prepare the agent to learn from interactions in the same way humans do. Check out the FULL CODES here.
class MemoryAgent:
def __init__(self):
self.episodic_memory = EpisodicMemory(capacity=50)
self.semantic_memory = SemanticMemory()
self.current_plan = []
self.session_count = 0
def perceive(self, user_input):
user_input = user_input.lower()
if any(word in user_input for word in ['recommend', 'suggest', 'what should']):
intent="recommendation"
elif any(word in user_input for word in ['remember', 'prefer', 'like', 'favorite']):
intent="preference_update"
elif any(word in user_input for word in ['do', 'complete', 'finish', 'task']):
intent="task_execution"
else:
intent="conversation"
return {'intent': intent, 'raw': user_input}
def plan(self, state):
intent = state['intent']
user_input = state['raw']
similar_episodes = self.episodic_memory.retrieve_similar(user_input, k=3)
plan = []
if intent == 'recommendation':
genre_prefs = {k: v for k, v in self.semantic_memory.preferences.items() if 'genre_' in k}
if genre_prefs:
best_genre = max(genre_prefs.items(), key=lambda x: x[1])[0]
plan.append(('recommend', best_genre.replace('genre_', '')))
else:
plan.append(('recommend', 'general'))
elif intent == 'preference_update':
genres = ['sci-fi', 'fantasy', 'mystery', 'romance', 'thriller']
detected_genre = next((g for g in genres if g in user_input), None)
if detected_genre:
plan.append(('update_preference', detected_genre))
elif intent == 'task_execution':
best_action = self.semantic_memory.get_best_action('task')
if best_action:
plan.append(('execute', best_action))
else:
plan.append(('execute', 'default'))
self.current_plan = plan
return planWe construct the agent’s perception and planning systems. We process the user’s input, detect intent, and create plans by leveraging the memories formed earlier. We begin shaping how the agent reasons and decides its next actions. Check out the FULL CODES here.
def act(self, action):
action_type, param = action
if action_type == 'recommend':
if param == 'general':
return f"Let me learn your preferences first! What genres do you enjoy?"
return f"Based on your preferences, I recommend exploring {param}!"
elif action_type == 'update_preference':
self.semantic_memory.update_preference(f'genre_{param}', 1.0, weight=1.0)
return f"Got it! I'll remember you enjoy {param}."
elif action_type == 'execute':
return f"Executing task with strategy: {param}"
return "Action completed"
def revise_plan(self, feedback):
if 'no' in feedback.lower() or 'wrong' in feedback.lower():
if self.current_plan:
action_type, param = self.current_plan[0]
if action_type == 'recommend':
genre_prefs = sorted(
[(k, v) for k, v in self.semantic_memory.preferences.items() if 'genre_' in k],
key=lambda x: x[1],
reverse=True
)
if len(genre_prefs) > 1:
new_genre = genre_prefs[1][0].replace('genre_', '')
self.current_plan = [('recommend', new_genre)]
return True
return False
def reflect(self, state, action, outcome, success):
self.episodic_memory.store(state['raw'], str(action), outcome)
self.semantic_memory.record_pattern(state['intent'], str(action), success)We define how the agent executes actions, revises its decisions when feedback contradicts expectations, and reflects by storing experiences. We continuously improve the agent’s behaviour by letting it learn from every turn. Through this loop, we make the system adaptive and self-correcting. Check out the FULL CODES here.
def run_session(self, user_inputs):
self.session_count += 1
print(f"\n{'='*60}")
print(f"SESSION {self.session_count}")
print(f"{'='*60}\n")
results = []
for i, user_input in enumerate(user_inputs, 1):
print(f"Turn {i}")
print(f"User: {user_input}")
state = self.perceive(user_input)
plan = self.plan(state)
if not plan:
print("Agent: I'm not sure what to do with that.\n")
continue
response = self.act(plan[0])
print(f"Agent: {response}\n")
success="recommend" in plan[0][0] or 'update' in plan[0][0]
self.reflect(state, plan[0], response, success)
results.append({
'turn': i,
'input': user_input,
'intent': state['intent'],
'action': plan[0],
'response': response
})
return resultsWe simulate real interactions in which the agent processes multiple user inputs within a single session. We watch the perceive → plan → act → reflect cycle unfold repeatedly. As we run sessions, we see how the agent gradually becomes more personalised and intelligent. Check out the FULL CODES here.
def evaluate_memory_usage(agent):
print("\n" + "="*60)
print("MEMORY ANALYSIS")
print("="*60 + "\n")
print(f"Episodic Memory:")
print(f" Total episodes stored: {len(agent.episodic_memory.episodes)}")
if agent.episodic_memory.episodes:
print(f" Oldest episode: {agent.episodic_memory.episodes[0]['timestamp']}")
print(f" Latest episode: {agent.episodic_memory.episodes[-1]['timestamp']}")
print(f"\nSemantic Memory:")
print(f" Learned preferences: {len(agent.semantic_memory.preferences)}")
for pref, value in sorted(agent.semantic_memory.preferences.items(), key=lambda x: x[1], reverse=True)[:5]:
print(f" {pref}: {value:.3f}")
print(f"\n Action patterns learned: {len(agent.semantic_memory.patterns)}")
print(f"\n Success rates by context-action:")
for key, stats in list(agent.semantic_memory.success_rates.items())[:5]:
if stats['total'] > 0:
rate = stats['success'] / stats['total']
print(f" {key}: {rate:.2%} ({stats['success']}/{stats['total']})")
def compare_sessions(results_history):
print("\n" + "="*60)
print("CROSS-SESSION ANALYSIS")
print("="*60 + "\n")
for i, results in enumerate(results_history, 1):
recommendation_quality = sum(1 for r in results if 'preferences' in r['response'].lower())
print(f"Session {i}:")
print(f" Turns: {len(results)}")
print(f" Personalized responses: {recommendation_quality}")We analyse how effectively the agent is using its memories. We check stored episodes, learned preferences, and success patterns to evaluate how the agent evolves. Check out the FULL CODES here.
def run_demo():
agent = MemoryAgent()
print("\n📚 SCENARIO: Agent learns user preferences over multiple sessions")
session1_inputs = [
"Hi, I'm looking for something to read",
"I really like sci-fi books",
"Can you recommend something?",
]
results1 = agent.run_session(session1_inputs)
session2_inputs = [
"I'm bored, what should I read?",
"Actually, I also enjoy fantasy novels",
"Give me a recommendation",
]
results2 = agent.run_session(session2_inputs)
session3_inputs = [
"What do you suggest for tonight?",
"I'm in the mood for mystery too",
"Recommend something based on what you know about me",
]
results3 = agent.run_session(session3_inputs)
evaluate_memory_usage(agent)
compare_sessions([results1, results2, results3])
print("\n" + "="*60)
print("EPISODIC MEMORY RETRIEVAL TEST")
print("="*60 + "\n")
query = "recommend sci-fi"
similar = agent.episodic_memory.retrieve_similar(query, k=3)
print(f"Query: '{query}'")
print(f"Retrieved {len(similar)} similar episodes:\n")
for ep in similar:
print(f" State: {ep['state']}")
print(f" Action: {ep['action']}")
print(f" Outcome: {ep['outcome'][:50]}...")
print()
if __name__ == "__main__":
print("="*60)
print("MEMORY & LONG-TERM AUTONOMY IN AGENTIC SYSTEMS")
print("="*60)
run_demo()
print("\n✅ Tutorial complete! Key takeaways:")
print(" • Episodic memory stores specific experiences")
print(" • Semantic memory generalizes patterns")
print(" • Agents improve recommendations over sessions")
print(" • Memory retrieval guides future decisions")We bring everything together by running multiple sessions and testing memory retrieval. We observe the agent improve across interactions and refine recommendations based on accumulated knowledge. This comprehensive demo illustrates how long-term autonomy naturally arises from the memory systems we have built.
In conclusion, we recognize how the combination of episodic and semantic memory enables us to build agents that learn continuously and make increasingly better decisions over time. We observe the agent refining recommendations, adapting plans, and retrieving past experiences to improve its responses session after session. Through these mechanisms, we see how long-term autonomy emerges from simple yet effective memory structures.
Check out the FULL CODES here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.